This is the multi-page printable view of this section. Click here to print.
Control Plane
1 - Entities
- 1. Assets
- 2. Policies
- 3. Contract definitions
- 4. Contract negotiations
- 5. Contract agreements
- 6. Catalog
- 7 Transfer processes
- 8 Endpoint Data References
- 9 Querying with
QuerySpecandCriterion
1. Assets
Assets are containers for metadata, they do not contain the actual bits and bytes. Say you want to offer a file to
the dataspace, that is physically located in an S3 bucket, then the corresponding Asset would contain metadata about
it, such as the content type, file size, etc. In addition, it could contain private properties, for when you want to
store properties on the asset, which you do not want to expose to the dataspace. Private properties will get ignored
when serializing assets out over DSP.
A very simplistic Asset could look like this:
{
"@context": {
"edc": "https://w3id.org/edc/v0.0.1/ns/"
},
"@id": "79d9c360-476b-47e8-8925-0ffbeba5aec2",
"properties": {
"somePublicProp": "a very interesting value"
},
"privateProperties": {
"secretKey": "this is secret information, never tell it to the dataspace!"
},
"dataAddress": {
"type": "HttpData",
"baseUrl": "http://localhost:8080/test"
}
}
The Asset also contains a DataAddress object, which can be understood as a “pointer into the physical world”. It
contains information about where the asset is physically located. This could be a HTTP URL, or a complex object. In the
S3 example, that DataAddress might contain the bucket name, region and potentially other information. Notice that the
schema of the DataAddress will depend on where the data is physically located, for instance a HttpDataAddress has
different properties from an S3 DataAddress. More precisely, Assets and DataAddresses are schemaless, so there is no
schema enforcement beyond a very basic validation. Read this document to learn about plugging in
custom validators.
A few things must be noted. First, while there isn’t a strict requirement for the @id to be a UUID, we highly
recommend using the JDK UUID implementation.
Second, never store access credentials such as passwords, tokens, keys etc. in the dataAddress or even the
privateProperties object. While the latter does not get serialized over DSP, both properties are persisted in the
database. Always use a HSM to store the credential, and hold a reference to the secret in the DataAddress. Checkout
the best practices for details.
By design, Assets are extensible, so users can store any metadata they want in it. For example, the properties object
could contain a simple string value, or it could be a complex object, following some custom schema. Be aware, that
unless specified otherwise, all properties are put under the edc namespace by default. There are some “well-known”
properties in the edc namespace: id, description, version, name, contenttype.
Here is an example of how an Asset with a custom property following a custom namespace would look like:
{
"@context": {
"edc": "https://w3id.org/edc/v0.0.1/ns/",
"sw": "http://w3id.org/starwars/v0.0.1/ns/"
},
"@id": "79d9c360-476b-47e8-8925-0ffbeba5aec2",
"properties": {
"faction": "Galactic Imperium",
"person": {
"name": "Darth Vader",
"webpage": "https://death.star"
}
}
}
(assuming the sw context contains appropriate definitions for faction and person).
Remember that upon ingress through the Management API, all JSON-LD objects get expanded, and the control plane only operates on expanded JSON-LD objects. The Asset above would look like this:
[
{
"@id": "79d9c360-476b-47e8-8925-0ffbeba5aec2",
"https://w3id.org/edc/v0.0.1/ns/properties": [
{
"https://w3id.org/starwars/v0.0.1/ns/faction": [
{
"@value": "Galactic Imperium"
}
],
"http://w3id.org/starwars/v0.0.1/ns/person": [
{
"http://w3id.org/starwars/v0.0.1/ns/name": [
{
"@value": "Darth Vader"
}
],
"http://w3id.org/starwars/v0.0.1/ns/webpage": [
{
"@value": "https://death.star"
}
]
}
]
}
]
}
]
This is important to keep in mind, because it means that Assets get persisted in their expanded form, and operations
performed on them (e.g. querying) in the control plane must also be done on the expanded form. For example, a query
targeting the sw:faction field from the example above would look like this:
{
"https://w3id.org/edc/v0.0.1/ns/filterExpression": [
{
"https://w3id.org/edc/v0.0.1/ns/operandLeft": [
{
"@value": "https://w3id.org/starwars/v0.0.1/ns/faction"
}
],
"https://w3id.org/edc/v0.0.1/ns/operator": [
{
"@value": "="
}
],
"https://w3id.org/edc/v0.0.1/ns/operandRight": [
{
"@value": "Galactic Imperium"
}
]
}
]
}
2. Policies
Policies are the EDC way of expressing that certain conditions may, must or must not be satisfied in certain situations. Policies are used to express what requirements a subject (e.g. a communication partner) must fulfill in order to be able to perform an action. For example, that the communication partner must be headquartered in the European Union.
Policies are ODRL serialized as JSON-LD. Thus, our previous example would look like this:
{
"@context": {
"edc": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "PolicyDefinition",
"policy": {
"@context": "http://www.w3.org/ns/odrl.jsonld",
"@type": "Set",
"duty": [
{
"target": "http://example.com/asset:12345",
"action": "use",
"constraint": {
"leftOperand": "headquarter_location",
"operator": "eq",
"rightOperand": "EU"
}
}
]
}
}
The duty object expresses the semantics of the constraint. It is a specialization of rule, which expresses either a
MUST (duty), MAY (permission) or MUST NOT (prohibition) relation. The action expresses the type of action for
which the rule is intended. Acceptable values for action are defined here,
but in EDC you’ll exclusively encounter "use".
The constraint object expresses logical relationship of a key (leftOperand), the value (righOperand) and the
operator. Multiple constraints can be linked with logical operators, see advanced policy
concepts. The leftOperand and rightOperand are completely arbitrary, only the
operator is limited to the following possible values: eq, neq, gt, geq, lt, leq, in, hasPart, isA,
isAllOf, isAnyOf, isNoneOf.
Please note that not all operators are always allowed, for example headquarter_location lt EU is nonsensical and
should result in an evaluation error, whereas headquarter_location isAnOf [EU, US] would be valid. Whether an
operator is valid is solely defined by the policy evaluation function, supplying
an invalid operator should raise an exception.
2.1 Policy vs PolicyDefinition
In EDC we have two general use cases under which we handle and persist policies:
- for use in contract definitions
- during contract negotiations
In the first case policies are ODRL objects and thus must have a uid property. They are typically used in contract
definitions.
Side note: the ODRL context available at
http://www.w3.org/ns/odrl.jsonldsimply definesuidas an alias to the@idproperty. This means, whether we useuidor@iddoesn’t matter, both expand to the same property@id.
However in the second case we are dealing with DCAT objects, that have no concept of Offers, Policies or Assets. Rather,
their vocabulary includes Datasets, Dataservices etc. So when deserializing those DCAT objects there is no way to
reconstruct Policy#uid, because the JSON-LD structure does not contain it.
To account for this, we defined the Policy class as value object that contains rules and other properties. In
addition, we have a PolicyDefinition class, which contains a Policy and an id property, which makes it an
entity.
2.2 Policy scopes and bindings
A policy scope is the “situation”, in which a policy is evaluated. For example, a policy may need to be evaluated when a contract negotiation is attempted. To do that, EDC defines certain points in the code called “scopes” to which policies are bound. These policy scopes (sometimes called policy evaluation points) are static, injecting/adding additional scopes is not possible. Currently, the following scopes are defined:
contract.negotiation: evaluated upon initial contract offer. Ensures that the consumer fulfills the contract policy.transfer.process: evaluated before starting a transfer process to ensure that the policy of the contract agreement is fulfilled. One example would be contract expiry.catalog: evaluated when the catalog for a particular participant agent is generated. Decides whether the participant has the asset in their catalog.request.contract.negotiation: evaluated on every request during contract negotiation between two control plane runtimes. Not relevant for end users.request.transfer.process: evaluated on every request during transfer establishment between two control plane runtimes. Not relevant for end users.request.catalog: evaluated upon an incoming catalog request. Not relevant for end users.provision.manifest.verify: evaluated during the precondition check for resource provisioning. Only relevant in advanced use cases.
A policy scope is a string that is used for two purposes:
- binding a scope to a rule type: implement filtering based on the
actionor theleftOperandof a policy. This determines for every rule inside a policy whether it should be evaluated in the given scope. In other words, it determines if a rule should be evaluated. - binding a policy evaluation function to a scope: if a policy is determined to be “in scope” by the previous step, the policy engine invokes the evaluation function that was bound to the scope to evaluate if the policy is fulfilled. In other words, it determines (implements) how a rule should be evaluated.
2.3 Policy evaluation functions
If policies are a formalized declaration of requirements, policy evaluation functions are the means to evaluate those requirements. They are pieces of Java code executed at runtime. A policy on its own only expresses the requirement, but in order to enforce it, we need to run policy evaluation functions.
Upon evaluation, they receive the operator, the rightOperand (or rightValue), the rule, and the PolicyContext. A
simple evaluation function that asserts the headquarters policy mentioned in the example above could look similar to
this:
import org.eclipse.edc.policy.engine.spi.AtomicConstraintFunction;
public class HeadquarterFunction implements AtomicConstraintFunction<Duty> {
public boolean evaluate(Operator operator, Object rightValue, Permission rule, PolicyContext context) {
if (!(rightValue instanceof String)) {
context.reportProblem("Right-value expected to be String but was " + rightValue.getClass());
return false;
}
if (operator != Operator.EQ) {
context.reportProblem("Invalid operator, only EQ is allowed!");
return false;
}
var participant = context.getContextData(ParticipantAgent.class);
var participantLocation = extractLocationClaim(participant); // EU, US, etc.
return participantLocation != null && rightValue.equalsIgnoreCase(participantLocation);
}
}
This particular evaluation function only accepts eq as operator, and only accepts scalars as rightValue, no list
types.
The ParticipantAgent is a representation of the communication counterparty that contains a set of verified claims. In
the example, extractLocationClaim() would look for a claim that contains the location of the agent and return it as
string. This can get quite complex, for example, the claim could contain geo-coordinates, and the evaluation function
would have to perform inverse address geocoding.
Other policies may require other context data than the participant’s location, for example an exact timestamp, or may even need a lookup in some third party system such as a customer database.
The same policy can be evaluated by different evaluation functions, if they are meaningful in different contexts (scopes).
NB: to write evaluation code for policies, implement the
org.eclipse.edc.policy.engine.spi.AtomicConstraintFunctioninterface. There is a second interface with the same name, but that is only used for internal use in thePolicyEvaluationEngine.
2.4 Example: binding an evaluation function
As we’ve learned, for a policy to be evaluated at certain points, we need to create
a policy (duh!), bind the policy to a scope, create a policy evaluation function,
and we need to bind the function to the same scope. The standard way of registering and binding policies is done in an
extension. For example, here we configure our HeadquarterFunction so that it evaluates our
headquarter_location function whenever someone tries to negotiate a contract:
public class HeadquarterPolicyExtension implements ServiceExtension {
@Inject
private RuleBindingRegistry ruleBindingRegistry;
@Inject
private PolicyEngine policyEngine;
private static final String HEADQUARTER_POLICY_KEY = "headquarter_location";
@Override
public void initialize() {
// bind the policy to the scope
ruleBindingRegistry.bind(HEADQUARTER_POLICY_KEY, NEGOTIATION_SCOPE);
// create the function object
var function = new HeadquarterFunction();
// bind the function to the scope
policyEngine.registerFunction(NEGOTIATION_SCOPE, Duty.class, HEADQUARTER_POLICY_KEY, function);
}
}
The code does two things: it binds the function key (= the leftOperand) to the negotiation scope, which means that the policy is “relevant” in that scope. Further, it binds the evaluation function to the same scope, which means the policy engine “finds” the function and executes it in the negotiation scope.
This example assumes, a policy object exists in the system, that has a leftOperand = headquarter_location. For details
on how to create policies, please check out the OpenAPI
documentation.
2.5 Advanced policy concepts
2.5.1 Pre- and Post-Evaluators
Pre- and post-validators are functions that are executed before and after the actual policy evaluation, respectively.
They can be used to perform preliminary evaluation of a policy or to enrich the PolicyContext. For example, EDC uses
pre-validators to inject DCP scope strings using dedicated ScopeExtractor objects.
2.5.2 Dynamic functions
These are very similar to AtomicConstraintFunctions, with one significant difference: they also receive the
left-operand as function parameter. This is useful when the function cannot be bound to a left-operand of a policy,
because the left-operand is not known in advance.
Let’s revisit our headquarter policy from earlier and change it a little:
{
"@context": {
"edc": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "PolicyDefinition",
"policy": {
"@context": "http://www.w3.org/ns/odrl.jsonld",
"@type": "Set",
"duty": [
{
"target": "http://example.com/asset:12345",
"action": "use",
"constraint": {
"or": [
{
"leftOperand": "headquarter.location",
"operator": "eq",
"rightOperand": "EU"
},
{
"leftOperand": "headerquarter.numEmployees",
"operator": "gt",
"rightOperand": 5000
}
]
}
}
]
}
}
This means two things. One, our policy has changed its semantics: now we require the headquarter to be in the EU, or to have more than 5000 employees.
2.5.3 Policy Validation and Evaluation Plan
By default ODRL policies are validated only in their structure (e.g. fields missing). In the latest
version of EDC an additional layer of validation has been introduced which leverages the PolicyEngine configuration in the runtime as described above
in order to have a more domain-specific validation.
Two APIs were added currently under v3.1alpha:
- Validate
- Evaluation Plan
2.5.3.1 Policy Validation
Given an input ODRL policy, the PolicyEngine checks potential issues that might arise in
the evaluation phase:
- a
leftOperandor anactionthat is not bound to a scope. - a
leftOperandthat is not bound to a function in thePolicyEngine.
Let’s take this policy as example:
{
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "PolicyDefinition",
"@id": "2",
"policy": {
"@context": "http://www.w3.org/ns/odrl.jsonld",
"@type": "Set",
"permission": [
{
"action": "use",
"constraint": {
"or": [
{
"leftOperand": "headquarter.location",
"operator": "eq",
"rightOperand": "EU"
}
]
}
}
]
}
}
Since we are using
@vocab, theleftOperandheadquarter.locationvaule defaults to theedcnamespace, i.e. will get transformed during JSON-LD expansion to"https://w3id.org/edc/v0.0.1/ns/headquarter.location"
and let’s assume that we didn’t bind the policy to any function or scope, the output of the validation might look like this:
{
"@type": "PolicyValidationResult",
"isValid": false,
"errors": [
"leftOperand 'https://w3id.org/edc/v0.0.1/ns/headquarter.location' is not bound to any scopes: Rule { Permission constraints: [Or constraint: [Constraint 'https://w3id.org/edc/v0.0.1/ns/headquarter.location' EQ 'EU']] } ",
"left operand 'https://w3id.org/edc/v0.0.1/ns/headquarter.location' is not bound to any functions: Rule { Permission constraints: [Or constraint: [Constraint 'https://w3id.org/edc/v0.0.1/ns/headquarter.location' EQ 'EU']] }"
],
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/",
"edc": "https://w3id.org/edc/v0.0.1/ns/",
"odrl": "http://www.w3.org/ns/odrl/2/"
}
}
Since the leftOperand is not bound to a scope and there is no function associated to it within any scope, we can deduce that the constraint will be filtered during evaluation.
The kind validation can be called using the /v3.1alpha/policydefinitions/{id}/validate or can be
enabled by default on policy definition creation.
The settings is
edc.policy.validation.enabledand is set tofalseby default
2.5.3.2 Policy Evaluation Plan
Even if the validation phase of a policy is successful, it might happen that evaluation of a Policy does not behave as expected if the PolicyEngine
was not configured properly.
One suche example would be if a function is bound only to a leftOperand in the catalog scope, but the desired behavior is to execute the policy function also in the contract.negotiation and in the transfer.process scopes.
In those scenarios, the new API called the “evaluation plan API” has been introduced to get an overview of all the steps that the PolicyEngine will take while evaluating a Policy within a scope without actually running the evaluation.
By using the same policy example, we could run an evaluation plan for the contract.negotiation scope:
POST https://controlplane-host:port/management/v3.1alpha/policydefinitions/2/evaluationplan
Content-Type: application/json
{
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/"
},
"policyScope": "contract.negotiation"
}
which gives this output:
{
"@type": "PolicyEvaluationPlan",
"preValidators": [],
"permissionSteps": {
"@type": "PermissionStep",
"isFiltered": false,
"filteringReasons": [],
"ruleFunctions": [],
"constraintSteps": {
"@type": "OrConstraintStep",
"constraintSteps": {
"@type": "AtomicConstraintStep",
"isFiltered": true,
"filteringReasons": [
"leftOperand 'https://w3id.org/edc/v0.0.1/ns/headquarter.location' is not bound to scope 'contract.negotiation'",
"leftOperand 'https://w3id.org/edc/v0.0.1/ns/headquarter.location' is not bound to any function within scope 'contract.negotiation'"
],
"functionParams": [
"'https://w3id.org/edc/v0.0.1/ns/headquarter.location'",
"EQ",
"'EU'"
]
}
},
"dutySteps": []
},
"prohibitionSteps": [],
"obligationSteps": [],
"postValidators": [],
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/",
"edc": "https://w3id.org/edc/v0.0.1/ns/",
"odrl": "http://www.w3.org/ns/odrl/2/"
}
}
which outlines two issues that would cause the constraint to be filtered out during the evaluation within the contract.negotiation scope:
- the
headquarter.locationhas no binding in theRuleBindingRegistrywithincontract.negotiation - the
headquarter.locationhas no function bound withincontract.negotiation
2.6 Bundled policy functions
2.6.1 Contract expiration function
3. Contract definitions
Contract definitions are how assets and policies are linked together. It is EDC’s way of expressing which policies are in effect for an asset. So when an asset (or several assets) are offered in the dataspace, a contract definition is used to express under what conditions they are offered. Those conditions are comprised of a contract policy and an access policy. The access policy determines, whether a participant will even get the offer, and the contract policy determines whether they can negotiate a contract for it. Those policies are referenced by ID, but foreign-key constrainta are not enforced. This means that contract definitions can be created ahead of time.
It is important to note that contract definitions are implementation details (i.e. internal objects), which means they never leave the realm of the provider, and they are never sent to the consumer via DSP.
- access policy: determines whether a particular consumer is offered an asset when making a catalog request. For example, we may want to restrict certain assets such that only consumers within a particular geography can see them. Consumers outside that geography wouldn’t even have them in their catalog.
- contract policy: determines the conditions for initiating a contract negotiation for a particular asset. Note that this only guarantees the successful initiation of a contract negotiation, it does not automatically guarantee the successful conclusion of it!
Contract definitions also contain an assetsSelector. THat is a query expression that defines all the assets that are
included in the definition, like an SQL SELECT statement. With that it is possible to configure the same set of
conditions (= access policy and contract policy) for a multitude of assets.
Please note that creating an assetSelector may require knowledge about the shape of an Asset and can get complex
fairly quickly, so be sure to read the chapter about querying.
Here is an example of a contract definition, that defines an access policy and a contract policy for assets id1, id2
and id3 that must contain the "foo" : "bar" property.
{
"@context": {
"edc": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "https://w3id.org/edc/v0.0.1/ns/ContractDefinition",
"@id": "test-id",
"edc:accessPolicyId": "access-policy-1234",
"edc:contractPolicyId": "contract-policy-5678",
"edc:assetsSelector": [
{
"@type": "https://w3id.org/edc/v0.0.1/ns/Criterion",
"edc:operandLeft": "id",
"edc:operator": "in",
"edc:operandRight": [
"id1",
"id2",
"id3"
]
},
{
"@type": "https://w3id.org/edc/v0.0.1/ns/Criterion",
"edc:operandLeft": "foo",
"edc:operator": "=",
"edc:operandRight": "bar"
}
]
}
The sample expresses that a set of assets identified by their ID be made available under the access policy
access-policy-1234 and contract policy contract-policy-5678, if they contain a property "foo" : "bar".
Note that asset selector expressions are always logically conjoined using an “AND” operation.
4. Contract negotiations
If a connector fulfills the contract policy, it may initiate the negotiation of a contract for a particular asset. During that negotiation, both parties can send offers and counter-offers that can contain altered terms (= policy) as any human would in a negotiation, and the counter-party may accept or reject them.
Contract negotiations have a few key aspects:
- they target one asset
- they take place between a provider and a consumer connector
- they cannot be changed by the user directly
- users can only decline, terminate or cancel them
As a side note it is also important to note that contract offers are ephemeral objects as they are generated on-the-fly for a particular participant, and they are never persisted in a database and thus cannot be queried through any API.
Contract negotiations are asynchronous in nature. That means after initiating them, they become (potentially long-running) stateful processes that are advanced by an internal state machine. The current state of the negotiation can be queried and altered through the management API.
Here’s a diagram of the state machine applied to contract negotiations:
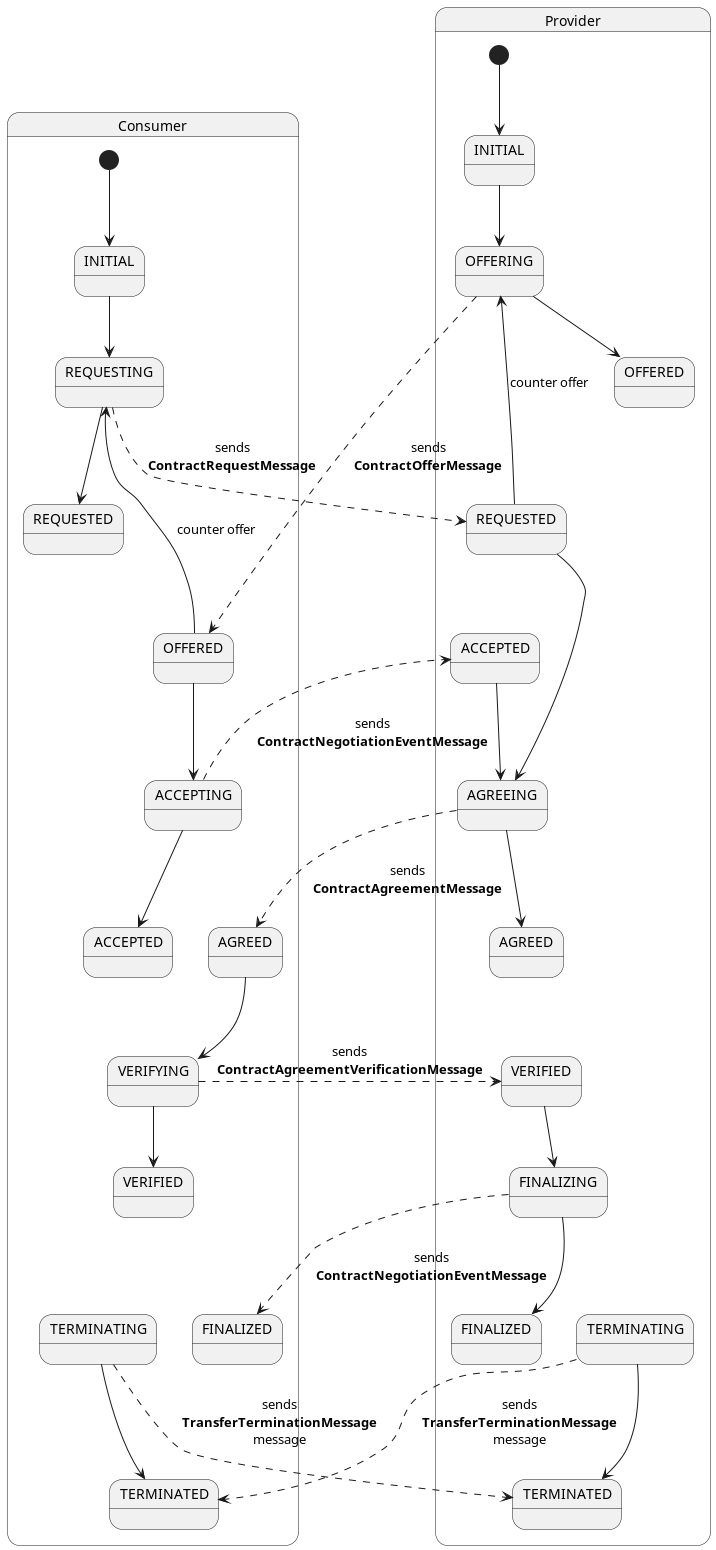
A contract negotiation can be initiated from the consumer side by sending a ContractRequest to the connector
management API.
{
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "ContractRequest",
"counterPartyAddress": "http://provider-address",
"protocol": "dataspace-protocol-http",
"policy": {
"@context": "http://www.w3.org/ns/odrl.jsonld",
"@type": "odrl:Offer",
"@id": "offer-id",
"assigner": "providerId",
"permission": [],
"prohibition": [],
"obligation": [],
"target": "assetId"
},
"callbackAddresses": [
{
"transactional": false,
"uri": "http://callback/url",
"events": [
"contract.negotiation"
],
"authKey": "auth-key",
"authCodeId": "auth-code-id"
}
]
}
The counterPartyAddress is the address where to send the ContractRequestMessage via the specified protocol (
currently dataspace-protocol-http)
The policy should hold the same policy associated to the data offering chosen from the catalog, plus
two additional properties:
assignerthe providersparticipantIdtargetthe asset (dataset) ID
In addition, the (optional) callbackAddresses array can be used to get notified about state changes of the
negotiation. Read more on callbacks in the section
about events and callbacks.
Note: if the
policysent by the consumer differs from the one expressed by the provider, the contract negotiation will fail and transition to aTERMINATEDstate.
5. Contract agreements
Once a contract negotiation is successfully concluded (i.e. it reaches the FINALIZED state), it “turns into” a
contract agreement. It is always the provider connector that gives the final approval. Contract agreements are
immutable objects that contain the final, agreed-on policy, the ID of the asset that the contract was negotiated for,
the IDs of the negotiation parties and the exact signing date.
Note that in future iterations contracts will be cryptographically signed to further support the need for immutability and non-repudiation.
Like contract definitions, contract agreements are entities that only exist within the bounds of a connector.
About terminating contracts: once a contract negotiation has reached a terminal
state
TERMINATED or FINALIZED, it becomes immutable. This could be compared to not being able to scratch a signature off a
physical paper contract. Cancelling or terminating a contract is therefor handled through other channels like eventing
systems. The semantics of cancelling a contract are highly individual to each dataspace and may even bring legal side
effects, so EDC cannot make an assumption here.
6. Catalog
The catalog contains the “data offerings” of a connector and one or multiple service endpoints to initiate a negotiation for those offerings.
Every data offering is represented by a Dataset object which
contains a policy and one or multiple Distribution
objects. A Distribution should be understood as a variant
or representation of the Dataset. For instance, if a file is accessible via multiple transmission channels from a
provider (HTTP and FTP), then each of those channels would be represented as a Distribution. Another example would be
image assets that are available in different file formats (PNG, TIFF, JPEG).
A DataService object specifies the endpoint where contract
negotiations and transfers are accepted by the provider. In practice, this will be the DSP endpoint of the connector.
The following example shows an HTTP response to a catalog request, that contains one offer that is available via two
channels HttpData-PUSH and HttpData-PULL.
catalog example
{
"@id": "567bf428-81d0-442b-bdc8-437ed46592c9",
"@type": "dcat:Catalog",
"dcat:dataset": [
{
"@id": "asset-2",
"@type": "dcat:Dataset",
"odrl:hasPolicy": {
"@id": "c2Vuc2l0aXZlLW9ubHktZGVm:YXNzZXQtMg==:MzhiYzZkNjctMDIyNi00OGJjLWFmNWYtZTQ2ZjAwYTQzOWI2",
"@type": "odrl:Offer",
"odrl:permission": [],
"odrl:prohibition": [],
"odrl:obligation": {
"odrl:action": {
"@id": "use"
},
"odrl:constraint": {
"odrl:leftOperand": {
"@id": "DataAccess.level"
},
"odrl:operator": {
"@id": "odrl:eq"
},
"odrl:rightOperand": "sensitive"
}
}
},
"dcat:distribution": [
{
"@type": "dcat:Distribution",
"dct:format": {
"@id": "HttpData-PULL"
},
"dcat:accessService": {
"@id": "a6c7f3a3-8340-41a7-8154-95c6b5585532",
"@type": "dcat:DataService",
"dcat:endpointDescription": "dspace:connector",
"dcat:endpointUrl": "http://localhost:8192/api/dsp",
"dct:terms": "dspace:connector",
"dct:endpointUrl": "http://localhost:8192/api/dsp"
}
},
{
"@type": "dcat:Distribution",
"dct:format": {
"@id": "HttpData-PUSH"
},
"dcat:accessService": {
"@id": "a6c7f3a3-8340-41a7-8154-95c6b5585532",
"@type": "dcat:DataService",
"dcat:endpointDescription": "dspace:connector",
"dcat:endpointUrl": "http://localhost:8192/api/dsp",
"dct:terms": "dspace:connector",
"dct:endpointUrl": "http://localhost:8192/api/dsp"
}
}
],
"description": "This asset requires Membership to view and SensitiveData credential to negotiate.",
"id": "asset-2"
}
],
"dcat:distribution": [],
"dcat:service": {
"@id": "a6c7f3a3-8340-41a7-8154-95c6b5585532",
"@type": "dcat:DataService",
"dcat:endpointDescription": "dspace:connector",
"dcat:endpointUrl": "http://localhost:8192/api/dsp",
"dct:terms": "dspace:connector",
"dct:endpointUrl": "http://localhost:8192/api/dsp"
},
"dspace:participantId": "did:web:localhost%3A7093",
"participantId": "did:web:localhost%3A7093",
"@context": {}
}
Catalogs are ephemeral objects, they are not persisted or cached on the provider side. Everytime a consumer participant makes a catalog request through DSP, the connector runtime has to evaluate the incoming request and build up the catalog specifically for that participant. The reason for this is that between two subsequent requests from the same participant, the contract definition or the claims or the participant could have changed.
The relevant component in EDC is the DatasetResolver, which resolves all contract definitions that are relevant to a
participant filtering out those where the participant does not satisfy the access policy and collects all the assets
therein.
In order to determine how an asset can be distributed, the resolver requires knowledge about the data planes that are
available. It uses the Dataplane Signaling Protocol to query them
and construct the list of
Distributions for an asset.
For details about the FederatedCatalog, please refer to its documentation.
7 Transfer processes
A TransferProcess is a record of the data sharing procedure between a consumer and a provider. As they traverse
through the system, they transition through several
states (TransferProcessStates).
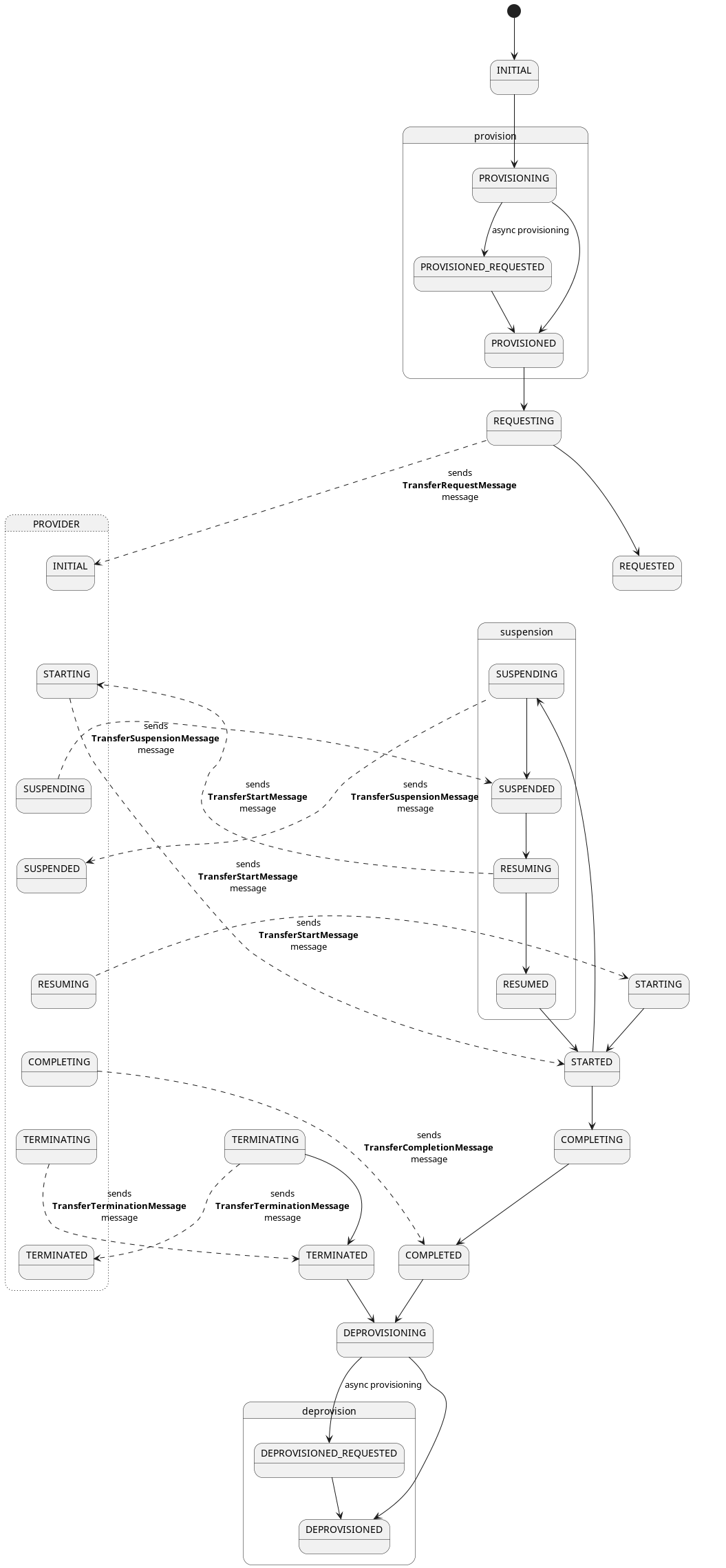
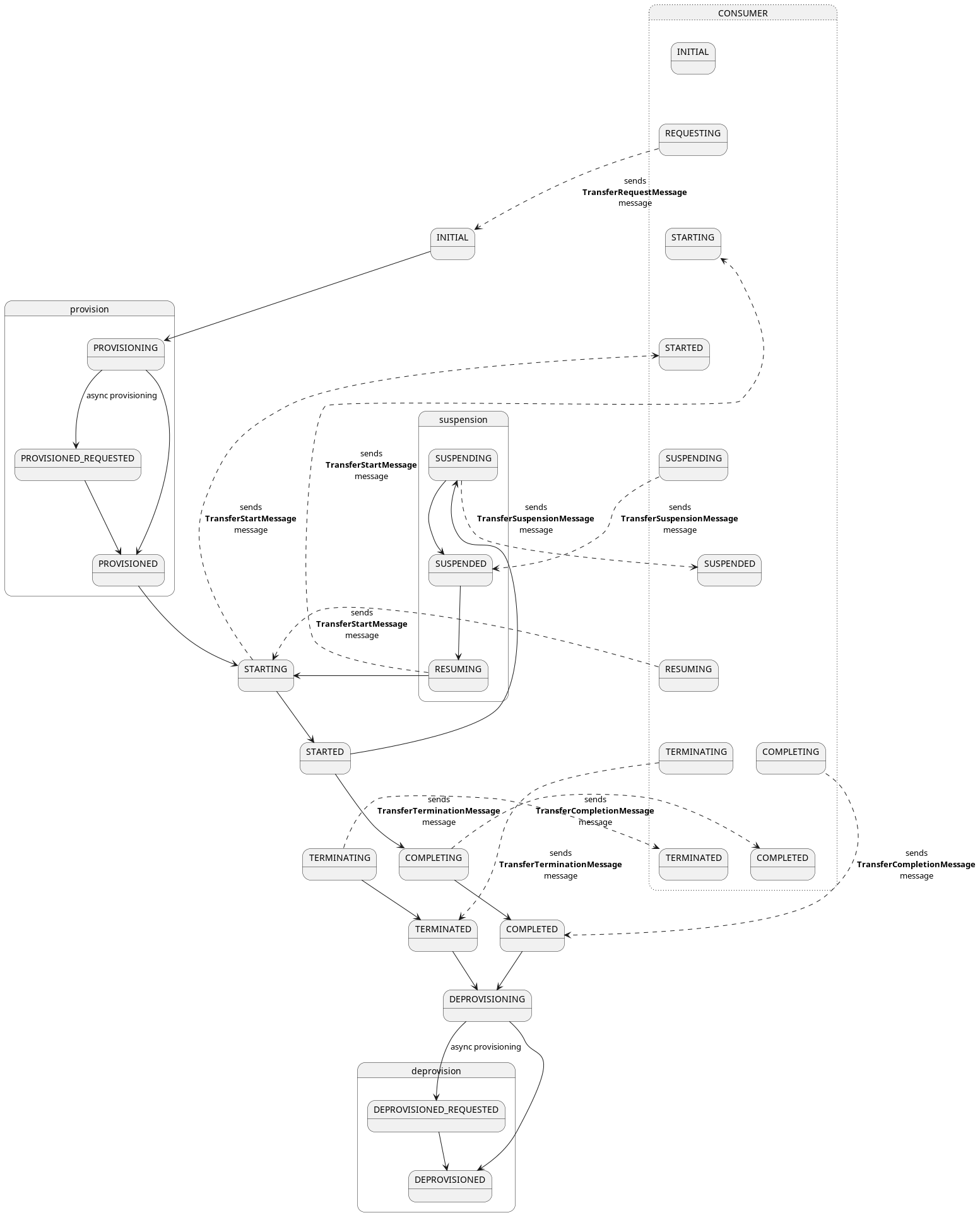
Once a contract is negotiated and an agreement is reached, the consumer connector may send a transfer initiate request to start the transfer. In the course of doing that, both parties may provision additional resources, for example deploying a temporary object store, where the provider should put the data. Similarly, the provider may need to take some preparatory steps, e.g. anonymizing the data before sending it out.
This is sometimes referred to as the provisioning phase. If no additional provisioning is needed, the transfer process simply transitions through the state with a NOOP.
Once that is done, the transfer begins in earnest. Data is transmitted according to the dataDestination, that was
passed in the initiate-request.
Once the transmission has completed, the transfer process will transition to the COMPLETED state, or - if an error
occurred - to the TERMINATED state.
The Management API provides several endpoints to manipulate data transfers.
Here is a diagram of the state machine applied to transfer processes on consumer side:
Here is a diagram of the state machine applied to transfer processes on provider side:
A transfer process can be initiated from the consumer side by sending a TransferRequest to the connector Management
API:
{
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "https://w3id.org/edc/v0.0.1/ns/TransferRequest",
"protocol": "dataspace-protocol-http",
"counterPartyAddress": "http://provider-address",
"contractId": "contract-id",
"transferType": "transferType",
"dataDestination": {
"type": "data-destination-type"
},
"privateProperties": {
"private-key": "private-value"
},
"callbackAddresses": [
{
"transactional": false,
"uri": "http://callback/url",
"events": [
"contract.negotiation",
"transfer.process"
],
"authKey": "auth-key",
"authCodeId": "auth-code-id"
}
]
}
where:
counterPartyAddress: the address where to send theTransferRequestMessagevia the specifiedprotocol( currentlydataspace-protocol-http)contractId: the ID of a previously negotiated contract agreement which is a result of the contract negotiation process.transferTypeand thedataDestinationdefine how and where the data transfer should happen.callbackAddressescustom hooks in order bo be notified about state transition of the transfer process.privateProperties: custom properties not shared with the counter party.
7.1 Transfer and data flows types
The transfer type defines the channel (Distribution) for the data transfer and it depends on the capabilities of
the data plane if it can be fulfilled. The transferType available for a
data offering is available in the dct:format of the Distribution when inspecting the catalog response.
Each transfer type also characterizes the type of the flow, which can be either pull or push and it’s data can be either finite or non-finite
7.1.1 Consumer Pull
A pull transfer is when the consumer receives information (in the form of a DataAddress) on how to retrieve data from
the Provider.
Then it’s up to the consumer to use this information for pulling the data.
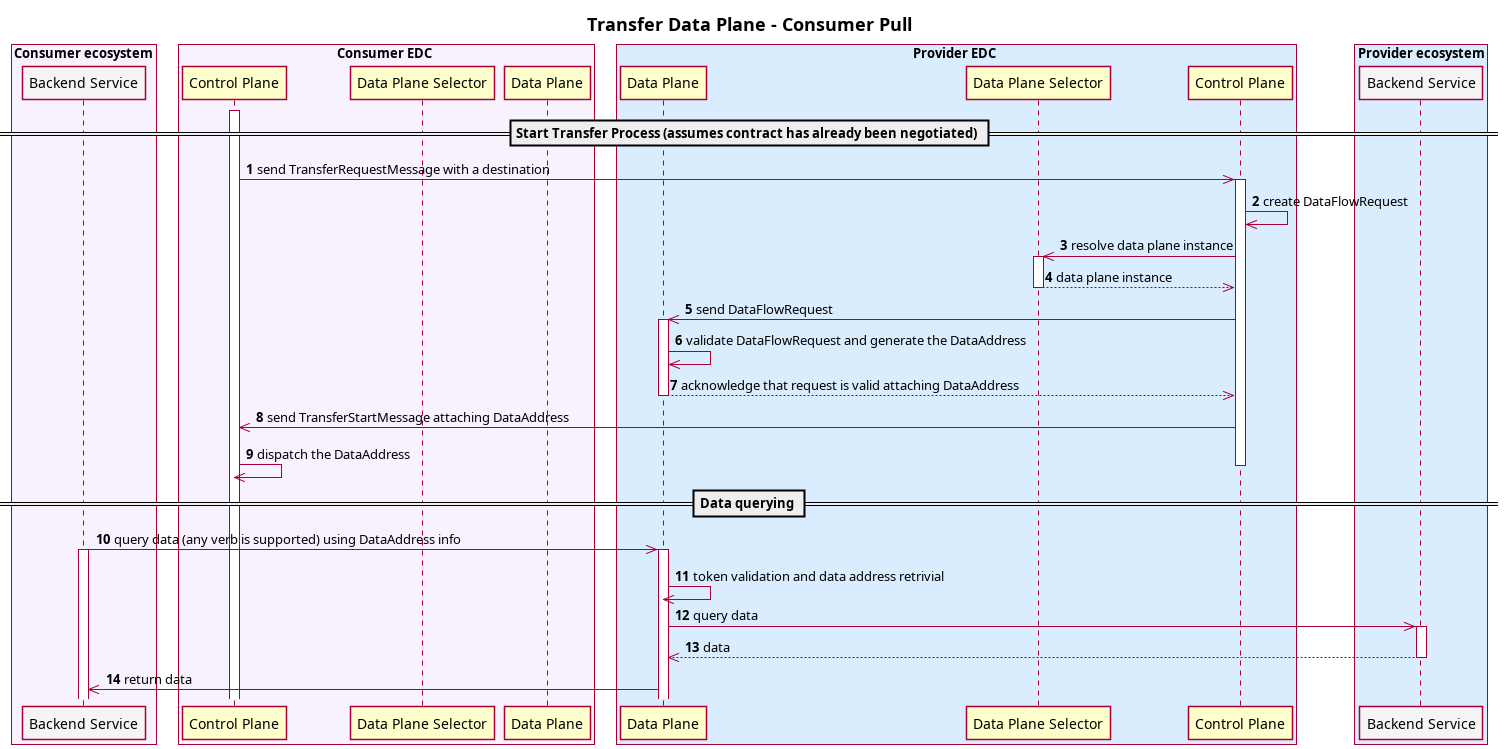
Provider and consumer agree to a contract (not displayed in the diagram)
- Consumer initiates the transfer process by sending a
TransferRequestMessage - The Provider Control Plane retrieves the
DataAddressof the actual data source and creates aDataFlowStartMessage. - The Provider Control Plane asks the selector which Data Plane instance can be used for this data transfer
- The Selector returns an eligible Data Plane instance (if any)
- Provider Control Plane sends the
DataFlowStartMessageto the selected Data Plane instance through data plane signaling protocol. - The Provider
DataPlaneManagervalidates the incoming request and delegates to theDataPlaneAuthorizationServicethe generation ofDataAddress, containing the information on location and authorization for fetching the data - The Provider Data Plane acknowledges the Provider control plane and attach the
DataAddressgenerated. - The Provider Control Plane notifies the start of the transfer attaching the
DataAddressin theTransferStartMessage. - The Consumer Control plane receives the
DataAddressand dispatch it accordingly to the configured runtime. Consumer can either decide to receive theDataAddressusing the eventing system callbacks using thetransfer.process.startedtype, or use the EDRs extensions for automatically store it on consumer control plane side. - With the informations in the
DataAddresssuch as theendpointUrland theAuthorizationdata can be fetched. - The Provider Data plane validates and authenticates the incoming request and retrieves the source
DataAddress. - The he provider data plane proxies the validated request to the configured backend in the source
DataAddress.
7.1.2 Provider Push
A push transfer is when the Provider data plane initiates sending data to the destination specified by the consumer.
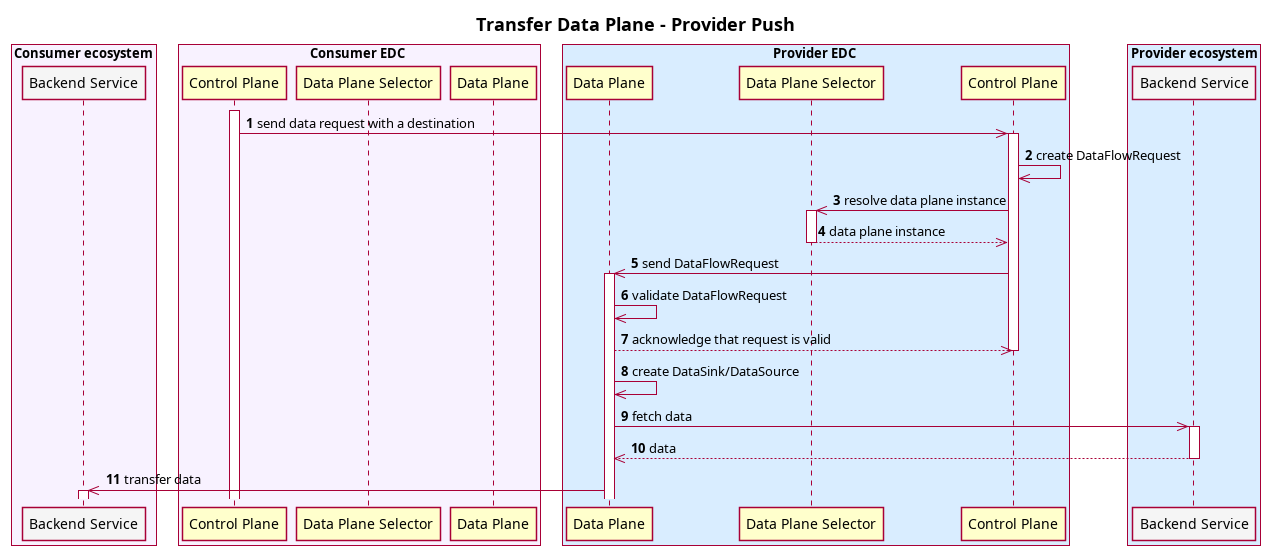
Provider and consumer agree to a contract (not displayed in the diagram)
- The Consumer initiates the transfer process, i.e. sends
TransferRequestMessagewith a destination DataAddress - The Provider Control Plane retrieves the
DataAddressof the actual data source and creates aDataFlowStartMessagewith both source and destinationDataAddress. - The Provider Control Plane asks the selector which Data Plane instance can be used for this data transfer
- The Selector returns an eligible Data Plane instance (if any)
- The Provider Control Plane sends the
DataFlowStartMessageto the selected Data Plane instance through data plane signaling protocol. - The Provider Data Plane validates the incoming request
- If request is valid, the Provider Data Plane returns acknowledgement
- The
DataPlaneManagerof the the Provider Data Plane processes the request: it creates aDataSource/DataSinkpair based on the source/destination data addresses - The Provider Data Plane fetches data from the actual data source (see
DataSource) - The Provider Data Plane pushes data to the consumer services (see
DataSink)
7.1.2 Finite and Non-Finite Data
The charaterization of the data applies to either push and pull transfers. Finite data transfers cause the transfer
process to transitition to the state COMPLETED, once the transmission has finished. For example a transfer of a single
file that is hosted and transferred into a cloud storage system.
Non-finite data means that once the transfer process request has been accepted by the provider the transfer process is
in the STARTED state until it gets terminated by the consumer or the provider. Exampes of Non-finite data are streams
or API endpoins.
On the provider side transfer processes can also be terminated by the policy monitor that periodically watches over the on going transfer and checks if the associated contract agreement still fulfills the contract policy.
7.2 About Data Destinations
A data destination is a description of where the consumer expects to find the data after the transfer completes. In a " provider-push" scenario this could be an object storage container, a directory on a file system, etc. In a “consumer-pull” scenario this would be a placeholder, that does not contain any information about the destination, as the provider “decides” which endpoint he makes the data available on.
A data address is a schemaless object, and the provider and the consumer need to have a common understanding of the
required fields. For example, if the provider is supposed to put the data into a file share, the DataAddress object
representing the data destination will likely contain the host URL, a path and possibly a file name. So both connectors
need to be “aware” of that.
The actual data transfer is handled by a data plane through extensions ( called “sources” and " sinks"). Thus, the way to establish that “understanding” is to make sure that both parties have matching sources and sinks. That means, if a consumer asks to put the data in a file share, the provider must have the appropriate data plane extensions to be able to perform that transfer.
If the provider connector does not have the appropriate extensions loaded at runtime, the transfer process will fail.
7.3 Transfer process callbacks
In order to get timely updates about status changes of a transfer process, we could simply poll the management API by
firing a GET /v*/transferprocesses/{tp-id}/state request every X amount of time. That will not only put unnecessary
load on the connector,
you may also run into rate-limiting situations, if the connector is behind a load balancer of some sort. Thus, we
recommend using event callbacks.
Callbacks must be specified when requesting to initiate the transfer:
{
// ...
"callbackAddresses": [
{
"transactional": false,
"uri": "http://callback/url",
"events": [
"transfer.process"
],
"authKey": "auth-key",
"authCodeId": "auth-code-id"
}
]
//...
}
Currently, we support the following events:
transfer.process.deprovisionedtransfer.process.completedtransfer.process.deprovisioningRequestedtransfer.process.initiatedtransfer.process.provisionedtransfer.process.provisioningtransfer.process.requestedtransfer.process.startedtransfer.process.terminated
The connector’s event dispatcher will send invoke the webhook specified in the uri field passing the event
payload as JSON object.
More info about events and callbacks can be found here.
8 Endpoint Data References
9 Querying with QuerySpec and Criterion
Most of the entities can be queried with the QuerySpec object, which is a generic way of expressing limit, offset,
sort and filters when querying a collection of objects managed by the EDC stores.
Here’s an example of how a QuerySpec object might look like when querying for Assets via management APIs:
{
"@context": {
"edc": "https://w3id.org/edc/v0.0.1/ns/"
},
"@type": "QuerySpec",
"limit": 1,
"offset": 1,
"sortField": "createdAt",
"sortOrder": "DESC",
"filterExpression": [
{
"operandLeft": "https://w3id.org/edc/v0.0.1/ns/description",
"operator": "=",
"operandRight": "This asset"
}
]
}
which filters by the description custom property being equals to This asset. The query also paginates the result
with limit and p set to 1. Additionally a sorting strategy is in place by createdAt property in descending order (
the default is ASC)
Note: Since custom properties are persisted in their expanded form, we have to use the expanded form also when querying.
The filterExpression property is a list of Criterion, which expresses a single filtering condition based on:
operandLeft: the property to filter onoperator: the operator to apply e.g.=operandRight: the value of the filtering
The supported operators are:
- Equal:
= - Not equal:
!= - In:
in - Like:
like - Ilike:
ilike(same aslikebut ignoring case sensitive) - Contains:
contains
Note: multiple filtering expressions are always logically conjoined using an “AND” operation.
The properties that can be expressed in the operandLeft of a Criterion depend on the shape of the entity that we are
want to query.
Note: nested properties are also supported using the dot notation.
QuerySpec can also be used when doing the catalog request using the querySpec property in the catalog request
payload for filtering the datasets:
{
"@context": {
"@vocab": "https://w3id.org/edc/v0.0.1/ns/"
},
"counterPartyAddress": "http://provider/api/dsp",
"protocol": "dataspace-protocol-http",
"counterPartyId": "providerId",
"querySpec": {
"filterExpression": [
{
"operandLeft": "https://w3id.org/edc/v0.0.1/ns/description",
"operator": "=",
"operandRight": "This asset"
}
]
}
}
Entities are backed by stores for doing CRUD operations. For each entity
there is an associated store interface (SPI). Most of the stores SPI have a query like method which takes a
QuerySpec type as input and returns the matched entities in a collection. Indivitual implementations are then
responsible for translating the QuerySpec to a proper fetching strategy.
The description on how the translation and mapping works will be explained in each implementation. Currently EDC support out of the box:
- In-memory stores (default implementation).
- SQL stores provied as extensions for each store, mostly tailored for and tested with PostgreSQL.
For guaranteeing the highest compatibility between store implementations, a base tests suite is provided for each store that each technology implementors need to fulfill in order to have a minimum usable store implementation.
2 - Policy Monitor
Some transfer types, once accepted by the provider, never reach the COMPLETED state. Streaming and HTTP transfers in consumer pull scenario are examples of this. In those scenarios the transfer will remain active (STARTED) until it gets terminated either manually by using the transfer processes management API, or automatically by the policy monitor, if it has been configured in the EDC runtime.
The policy monitor (PolicyMonitorManager) is a component that watches over on-going transfers on the provider side and ensures that the associated policies are still valid. The default implementation of the policy monitor tracks the monitored transfer processes in it’s own entity PolicyMonitorEntry stored in the PolicyMonitorStore.
Once a transfer process transition to the STARTED state on the provider side, the policy monitor gets notified through the eventing system of EDC and start tracking transfer process. For each monitored transfer process in the STARTED state the policy monitor retrieves the policy associated (through contract agreement) and runs the Policy Engine using the policy.monitor as scope.
If the policy is no longer valid, the policy monitor marks the transfer process for termination (TERMINATING) and stops tracking it.
The data plane also gets notified through the data plane signaling protocol about the termination of the transfer process, and if accepted by the data plane, the data transfer terminates as well.
Note for implementors
Implementors that want a Policy function to be evaluated at the policy monitor layer need to bind such function to the policy.monitor scope.
Note that because the policy evaluation happens in the background, the PolicyContext does not contain ParticipantAgent as context data. This means that the Policy Monitor cannot evaluate policies that involve VerifiableCredentials.
Currently the only information published in the PolicyContext available for functions in the policy.monitor scope are the ContractAgreement, and the Instant at the time of the evaluation.
A bundled example of a Policy function that runs in the policy.monitor scope is the ContractExpiryCheckFunction which checks if the contract agreement is not expired.
3 - Protocol Extensions
The EDC officially supports the Dataspace protocol using the HTTPs bindings, but since it is an extensible platform, multiple protocol implementations can be supported for inter-connectors communication. Each supported protocols is identified by a unique key used by EDC for dispatching a remote message.
1. RemoteMessage
At the heart of EDC message exchange mechanism lies the RemoteMessage interface, which describes the protocol, the counterPartyAddress and the counterPartyId used for a message delivery.
RemoteMessage extensions can be divided in three groups:
- Catalog (
catalog-spi) - Contract negotiation (
contract-spi) - Transfer process (
transfer-spi)
Each RemoteMessage is:
- Delivered to the counter-party using a RemoteMessageDispatcher.
- Received by the counter-party through the protocol implementation (e.g HTTP) and handled by the protocol services layer.
1.1 Delivering messages with RemoteMessageDispatcher
Each protocol implements a RemoteMessageDispatcher:
public interface RemoteMessageDispatcher {
String protocol();
<T, M extends RemoteMessage> CompletableFuture<StatusResult<T>> dispatch(Class<T> responseType, M message);
}
and it is registered in the RemoteMessageDispatcherRegistry, where it gets associated to the protocol defined in RemoteMessageDispatcher#protocol.
Internally EDC uses the RemoteMessageDispatcherRegistry whenever it needs to deliver a RemoteMessage to the counter-party. The RemoteMessage then gets routed to the right RemoteMessageDispatcher based on the RemoteMessage#getProtocol property.
EDC also uses
RemoteMessageDispatcherRegistryfor non-protocol messages when dispatching event callbacks
1.2 Handling incoming messages with protocol services
On the ingress side, protocol implementations should be able to receive messages through the network (e.g. API Controllers), deserialize them into the corresponding RemoteMessages and then dispatching them to the right protocol service.
Protocol services are three:
CatalogProtocolServiceContractNegotiationProtocolServiceTransferProcessProtocolService
which handle respectively Catalog, ContractNegotiation and TransferProcess messages.
2. DSP protocol implementation
The Dataspace protocol protocol implementation is available under the data-protocol/dsp subfolder in the Connector repository and it is identified by the key dataspace-protocol-http.
It extends the RemoteMessageDispatcher with the interface DspHttpRemoteMessageDispatcher (dsp-spi), which adds an additional method for registering message handlers.
The implementation of the three DSP specifications:
is separated in multiple extension modules grouped by specification.
This allows for example to build a runtime that only serves a dsp catalog requests useful the Management Domains scenario.
Each specification implementation defines handlers, transformers for RemoteMessages and exposes HTTP endpoints.
The
dspimplementation also provide HTTP endpoints for the DSP common functionalities.
2.1 RemoteMessage handlers
Handlers map a RemoteMessage to an HTTP Request and instruct the DspHttpRemoteMessageDispatcher how to extract the response body to a desired type.
2.2 HTTP endpoints
Each dsp-*-http-api module exposes its own API Controllers for serving the specification requests. Each request handler transforms the JSON-LD in input, if present, into a RemoteMessage and then calls the protocol service layer.
2.2 RemoteMessage transformers
Each dsp-*-transform module registers in the DSP API context Transformers for mapping JSON-LD objects from and to RemoteMessages.